
Профессор Арвинд Нараянан о змеином масле в сфере ИИ
("Змеиным маслом" раньше торговали аптекари-мошенники, теперь этот эвфемизм означает распиаренную и неэффективную пустышку)
ИИ — зонтичный термин для целого семейства технологий. Некоторые из них действительно показывают впечатляющие результаты, чем добавляют хайпа в общественную дискуссию. Опрос общественного мнения показывает, что американцы ожидают автоматизации всех профессий уже через 10 лет.
Компании используют этот хайп и добавляют название "ИИ" в свои продукты, даже если там на самом деле нет ИИ или его эффективность низка.
Нараянан грубо делит применения ИИ на три группы:
— связанные с восприятием (распознавание треков, лиц, речи) — здесь эффективность ИИ уже довольно высока;
— автоматизированное оценивание (детекция спама, хейтспича, рекомендации контента) — в этих задачах ИИ никогда не будет на 100% точен, это надо принять;
— попытка предсказать социальные процессы исходя из исторических данных (прогнозирование преступлений, рецидивов, эффективности сотрудников) — а вот это, по мнению Арвинда, и есть то самое "змеиное масло"; это тот тип задач для ИИ, которые он не сможет решить, сколько бы данных в него не загружали.
Во многих случаях такие задачи проще и эффективнее решаются простыми линейными формулами. Яркий пример: американское исследование 4200 семей. Учёные собрали 13 тысяч параметров, наблюдая за тысячами семей. И затем попробовали найти формулу, которая могла бы предсказать успешность ребенка, исходя из информации о семье, в которой он рос. В итоге самые точные математические модели, учитывающие 13 тысяч параметров, оказались настолько же точными в прогнозах, как и линейная регрессия, учитывающая всего 4 параметра. Похожая картина получается и с прогнозированием других социальных явлений, таких как вероятность рецидивов или лишения прав.
Вывод — ИИ мощный инструмент, но он не подходит для прогнозирования социальных явлений. В большинстве случаев "ручное" оценивание настолько же точно, но при этом более прозрачно.
Понятная презентация на 20 слайдов
("Змеиным маслом" раньше торговали аптекари-мошенники, теперь этот эвфемизм означает распиаренную и неэффективную пустышку)
ИИ — зонтичный термин для целого семейства технологий. Некоторые из них действительно показывают впечатляющие результаты, чем добавляют хайпа в общественную дискуссию. Опрос общественного мнения показывает, что американцы ожидают автоматизации всех профессий уже через 10 лет.
Компании используют этот хайп и добавляют название "ИИ" в свои продукты, даже если там на самом деле нет ИИ или его эффективность низка.
Нараянан грубо делит применения ИИ на три группы:
— связанные с восприятием (распознавание треков, лиц, речи) — здесь эффективность ИИ уже довольно высока;
— автоматизированное оценивание (детекция спама, хейтспича, рекомендации контента) — в этих задачах ИИ никогда не будет на 100% точен, это надо принять;
— попытка предсказать социальные процессы исходя из исторических данных (прогнозирование преступлений, рецидивов, эффективности сотрудников) — а вот это, по мнению Арвинда, и есть то самое "змеиное масло"; это тот тип задач для ИИ, которые он не сможет решить, сколько бы данных в него не загружали.
Во многих случаях такие задачи проще и эффективнее решаются простыми линейными формулами. Яркий пример: американское исследование 4200 семей. Учёные собрали 13 тысяч параметров, наблюдая за тысячами семей. И затем попробовали найти формулу, которая могла бы предсказать успешность ребенка, исходя из информации о семье, в которой он рос. В итоге самые точные математические модели, учитывающие 13 тысяч параметров, оказались настолько же точными в прогнозах, как и линейная регрессия, учитывающая всего 4 параметра. Похожая картина получается и с прогнозированием других социальных явлений, таких как вероятность рецидивов или лишения прав.
Вывод — ИИ мощный инструмент, но он не подходит для прогнозирования социальных явлений. В большинстве случаев "ручное" оценивание настолько же точно, но при этом более прозрачно.
Понятная презентация на 20 слайдов
Twitter
Arvind Narayanan
Much of what’s being sold as "AI" today is snake oil. It does not and cannot work. In a talk at MIT yesterday, I described why this happening, how we can recognize flawed AI claims, and push back. Here are my annotated slides: cs.princeton.edu/~arvindn/talks…
Отличный материал для журналистов, блогеров, исследователей и всех, кто читает и пишет материалы про ИИ: AI Coverage Best Practices, According to AI Researchers.
Прочитайте сами и передайте своим друзьям и коллегам. И не читайте плохо написанные тексты про ИИ.
Что ёще почитать по теме:
— Как распознать мошенничество в сфере ИИ
— 7 ошибок, которые допускают все, кто пытаются предсказать будущее ИИ
— Несколько советов для журналистов, пишущих об ИИ
— Bullshit news в технологической журналистике (и ещё)
Прочитайте сами и передайте своим друзьям и коллегам. И не читайте плохо написанные тексты про ИИ.
Что ёще почитать по теме:
— Как распознать мошенничество в сфере ИИ
— 7 ошибок, которые допускают все, кто пытаются предсказать будущее ИИ
— Несколько советов для журналистов, пишущих об ИИ
— Bullshit news в технологической журналистике (и ещё)
Forwarded from Цифровая тень
Amnesty International опубликовала 60-страничный отчет о Google и Facebook с красноречивым названием "Гиганты слежки".
Для миллиардов людей по всему миру именно сервисы Google и Facebook являются проводниками в Интернет. И хотя эти сервисы в основном бесплатны, пользователи платят за них свою цену, предоставляя компаниям свои персональные данные.
Правозащитники утверждают, что обе компании угрожают правам человека, в том числе свободе выражения мнения и свободе мысли. Виной тому — бизнес-модель, основанная на массированном сборе данных о поведении пользователей, которые затем обрабатываются с помощью сложных алгоритмов и используются, в первую очередь, для получения дохода от рекламы.
Такая бизнес-модель позволила двум гигантам сконцентрировать огромную власть, включая финансовую мощь, политическое влияние и способность формировать цифровой опыт миллиардов людей. Это привело к беспрецедентной асимметрии знаний между компаниями и пользователями Интернета - как утверждает исследовательница Шошана Зубофф (Shoshana Zuboff): «Они знают о нас всё; мы не знаем о них почти ничего».
Для миллиардов людей по всему миру именно сервисы Google и Facebook являются проводниками в Интернет. И хотя эти сервисы в основном бесплатны, пользователи платят за них свою цену, предоставляя компаниям свои персональные данные.
Правозащитники утверждают, что обе компании угрожают правам человека, в том числе свободе выражения мнения и свободе мысли. Виной тому — бизнес-модель, основанная на массированном сборе данных о поведении пользователей, которые затем обрабатываются с помощью сложных алгоритмов и используются, в первую очередь, для получения дохода от рекламы.
Такая бизнес-модель позволила двум гигантам сконцентрировать огромную власть, включая финансовую мощь, политическое влияние и способность формировать цифровой опыт миллиардов людей. Это привело к беспрецедентной асимметрии знаний между компаниями и пользователями Интернета - как утверждает исследовательница Шошана Зубофф (Shoshana Zuboff): «Они знают о нас всё; мы не знаем о них почти ничего».
Amnesty International
Surveillance giants: How the business model of Google and Facebook threatens human rights - Amnesty International
Google and Facebook help connect the world and provide crucial services to billions. To participate meaningfully in today’s economy and society, and to realize their human rights, people rely on access to the internet—and to the tools Google and Facebook…
Forwarded from wintermute
сотрудники ГК "Нейроботикс" и МФТИ обучают нейросеть воссоздавать изображения по электрической активности мозга в режиме реального времени, снимая сигналы непосредственно с нейронов с помощью электроэнцефалографии (ЭЭГ)
https://youtu.be/nf-P3b2AnZw
теоретически, я думаю, можно будет таким же образом вынимать из мозга воспоминания (наверное). первое, что приходит на ум в прикладном смысле - воссоздание облика разных людей, к примеру, преступников, без посредников в виде художников или составителей фотороботов. человек просто думает, нейросеть рисует
пока выглядит не очень, но вообще это экспериментальные пробы, так что впечатляет
https://i.redd.it/hztbaqe7dxz31.png
минорити репорт все ближе
https://techxplore.com/news/2019-10-neural-network-reconstructs-human-thoughts.html
https://youtu.be/nf-P3b2AnZw
теоретически, я думаю, можно будет таким же образом вынимать из мозга воспоминания (наверное). первое, что приходит на ум в прикладном смысле - воссоздание облика разных людей, к примеру, преступников, без посредников в виде художников или составителей фотороботов. человек просто думает, нейросеть рисует
пока выглядит не очень, но вообще это экспериментальные пробы, так что впечатляет
https://i.redd.it/hztbaqe7dxz31.png
минорити репорт все ближе
https://techxplore.com/news/2019-10-neural-network-reconstructs-human-thoughts.html
YouTube
Нейросети научили "читать мысли" в режиме реального времени
https://www.biorxiv.org/content/10.1101/787101v2
В рамках проекта "Ассистивные нейротехнологии" NeuroNet НТИ сотрудники ГК "Нейроботикс" и МФТИ обучили нейросети воссоздавать изображения по электрической активности мозга, ранее такие эксперименты никем не…
В рамках проекта "Ассистивные нейротехнологии" NeuroNet НТИ сотрудники ГК "Нейроботикс" и МФТИ обучили нейросети воссоздавать изображения по электрической активности мозга, ранее такие эксперименты никем не…
Forwarded from data stories
All Hail The Algorithm
Al Jazeera сделали документальный проект о алгоритмах в нашей жизни: «Пятисерийная документалка, исследующая воздействие алгоритмов на нашу жизнь»
– Первая серия про то, можем ли мы доверять алгоритмам
– Вторая про «империи данных»: колонизацию большими технологическими компаниями других стран. Там в качестве спикера есть Улисес Мехиас, интервью с которым я делал некоторое время назад.
– Третья про роль алгоритмов в политической манипуляции и фейк ньюс
– Четвертая про опасности биометрических технологий (немного о технологиях распознавания лиц я писал тут)
– Пятая про уловки дизайна
Al Jazeera сделали документальный проект о алгоритмах в нашей жизни: «Пятисерийная документалка, исследующая воздействие алгоритмов на нашу жизнь»
– Первая серия про то, можем ли мы доверять алгоритмам
– Вторая про «империи данных»: колонизацию большими технологическими компаниями других стран. Там в качестве спикера есть Улисес Мехиас, интервью с которым я делал некоторое время назад.
– Третья про роль алгоритмов в политической манипуляции и фейк ньюс
– Четвертая про опасности биометрических технологий (немного о технологиях распознавания лиц я писал тут)
– Пятая про уловки дизайна
Aljazeera
All Hail the Algorithm
A five-part series exploring the impact of algorithms on our everyday lives
Forwarded from Цифровая тень
Google всегда уверял, что не вмешивается работу своего поискового алгоритма. Оказалось, что это не так
Каждую минуту пользователи вводят около 3,8 млн. запросов в поисковую строку Google. Полагаясь на его алгоритмы, они надеются получить релевантные результаты о ценах на отели или лечении от рака, или о последних новостях политики.
Влияние этих строк кода на глобальную экономику поистине огромно: миллионы людей обращаются к информации, найденной в Интернете, и именно она является отправной точкой для денежных потоков в миллиарды долларов.
Руководители Google неоднократно заявляли, – в том числе в свидетельских показаниях в Конгрессе - что алгоритмы являются объективными и, по сути, автономными, не подверженными человеческим предрассудкам или коммерческим соображениям.
Компания заявляет, что люди не влияют на поисковую выдачу и ранжирование результатов. Журналисты WSJ выяснили, что в последнее время Google все больше вмешивается в результаты поиска — и в гораздо большей степени, чем компания признает публично.
Часто это происходит под давлением со стороны крупного бизнеса и правительств различных стран. Google стал чаще прибегать к подобным действиям после выборов 2016 года в США и скандалов о дезинформации в Интернете.
По словам одного из руководителей Google, который занимается поиском, внутреннее расследование 2016 года в Google показало, что до четверти поисковых запросов возвращают какую-то дезинформацию. В процентном отношении это не так уж и много, но, учитывая огромный объем поисковых запросов в Google, это составило бы почти два миллиарда поисковых запросов в год. Для сравнения: роль Facebook оказалась предметом слушаний Конгресса после скандала с российской дезинформацией, которую просмотрели 126 миллионов пользователей.
Кратко о том, что выяснили журналисты издания:
• Алгоритмы поиска отдают предпочтение крупным компаниям по сравнению с более мелкими, поддерживая некоторые крупные веб-сайты, такие как Amazon.com Inc. и Facebook Inc
• Инженеры Google регулярно вносят скрытые коррективы в информацию, которую компания все чаще размещает параллельно основным результатам поиска: в предложения по автозаполнению, в так называемые «панели знаний» и «избранные фрагменты», в результаты новостей.
• Существуют чёрные списки для удаления из результатов поиска некоторых сайтов. И это не касается случаев, когда сайты блокируются из-за нарушения законодательства США или других стран.
• В режиме автозаполнения - функции, которая предсказывает слова по мере того, как пользователь вводит запрос, – инженеры Google создали алгоритмы и чёрные списки, чтобы отсеять сомнительные с точки зрения компании предложения по спорным вопросам.
• Сотрудники и руководители Google, включая соучредителей Ларри Пейджа и Сергея Брина, не пришли к единому мнению о том, в какой степени стоит вмешиваться в результаты поиска.
• Для оценки результатов поиска в Google работают тысячи низкооплачиваемых подрядчиков, цель которых, по словам компании, заключается в оценке качества алгоритмов ранжирования. Подрядчики утверждаю: компания даёт им понять, что именно она считает правильным ранжированием результатов.
Каждую минуту пользователи вводят около 3,8 млн. запросов в поисковую строку Google. Полагаясь на его алгоритмы, они надеются получить релевантные результаты о ценах на отели или лечении от рака, или о последних новостях политики.
Влияние этих строк кода на глобальную экономику поистине огромно: миллионы людей обращаются к информации, найденной в Интернете, и именно она является отправной точкой для денежных потоков в миллиарды долларов.
Руководители Google неоднократно заявляли, – в том числе в свидетельских показаниях в Конгрессе - что алгоритмы являются объективными и, по сути, автономными, не подверженными человеческим предрассудкам или коммерческим соображениям.
Компания заявляет, что люди не влияют на поисковую выдачу и ранжирование результатов. Журналисты WSJ выяснили, что в последнее время Google все больше вмешивается в результаты поиска — и в гораздо большей степени, чем компания признает публично.
Часто это происходит под давлением со стороны крупного бизнеса и правительств различных стран. Google стал чаще прибегать к подобным действиям после выборов 2016 года в США и скандалов о дезинформации в Интернете.
По словам одного из руководителей Google, который занимается поиском, внутреннее расследование 2016 года в Google показало, что до четверти поисковых запросов возвращают какую-то дезинформацию. В процентном отношении это не так уж и много, но, учитывая огромный объем поисковых запросов в Google, это составило бы почти два миллиарда поисковых запросов в год. Для сравнения: роль Facebook оказалась предметом слушаний Конгресса после скандала с российской дезинформацией, которую просмотрели 126 миллионов пользователей.
Кратко о том, что выяснили журналисты издания:
• Алгоритмы поиска отдают предпочтение крупным компаниям по сравнению с более мелкими, поддерживая некоторые крупные веб-сайты, такие как Amazon.com Inc. и Facebook Inc
• Инженеры Google регулярно вносят скрытые коррективы в информацию, которую компания все чаще размещает параллельно основным результатам поиска: в предложения по автозаполнению, в так называемые «панели знаний» и «избранные фрагменты», в результаты новостей.
• Существуют чёрные списки для удаления из результатов поиска некоторых сайтов. И это не касается случаев, когда сайты блокируются из-за нарушения законодательства США или других стран.
• В режиме автозаполнения - функции, которая предсказывает слова по мере того, как пользователь вводит запрос, – инженеры Google создали алгоритмы и чёрные списки, чтобы отсеять сомнительные с точки зрения компании предложения по спорным вопросам.
• Сотрудники и руководители Google, включая соучредителей Ларри Пейджа и Сергея Брина, не пришли к единому мнению о том, в какой степени стоит вмешиваться в результаты поиска.
• Для оценки результатов поиска в Google работают тысячи низкооплачиваемых подрядчиков, цель которых, по словам компании, заключается в оценке качества алгоритмов ранжирования. Подрядчики утверждаю: компания даёт им понять, что именно она считает правильным ранжированием результатов.
Forwarded from Городские данные (Andrey Karmatsky)
https://vc.ru/transport/94045-issledovateli-v-ssha-svyazali-poyavlenie-uber-v-gorode-s-rostom-potrebleniya-alkogolya-mestnymi-zhitelyami
«Экономисты Джейкоб Бургдорф и Конор Леннон из Луисвиллского университета и Кит Тельцер из Университета штата Джорджия решили выяснить, есть ли связь между появлением в городе такси-сервиса Uber с увеличением потребления алкоголя местными жителями.
Чрезмерное употребление алкоголя (когда человек выпивает четыре-пять напитков за два часа) увеличилось на 8%, а случаи пьянства (три и более случаев алкогольного опьянения в месяц) — на 9%. В городах, где нет общественного транспорта, появление Uber привело к росту потребления алкоголя в среднем на 5%»
«Экономисты Джейкоб Бургдорф и Конор Леннон из Луисвиллского университета и Кит Тельцер из Университета штата Джорджия решили выяснить, есть ли связь между появлением в городе такси-сервиса Uber с увеличением потребления алкоголя местными жителями.
Чрезмерное употребление алкоголя (когда человек выпивает четыре-пять напитков за два часа) увеличилось на 8%, а случаи пьянства (три и более случаев алкогольного опьянения в месяц) — на 9%. В городах, где нет общественного транспорта, появление Uber привело к росту потребления алкоголя в среднем на 5%»
vc.ru
Исследователи в США связали появление Uber в городе с ростом потребления алкоголя местными жителями — Транспорт на vc.ru
Но и количество аварий с нетрезвыми водителями сокращается.
If Facebook were around in the 1930s, it would have allowed Hitler to post 30-second ads on his “solution” to the “Jewish problem.”
Все мы знаем Сашу Барона Коэна как талантливого актёра и сатирика. На днях он раскрылся в новом амплуа: выступил на международном правозащитном саммите с критикой интернет-компаний, которые зарабатывают на хейтспиче и фейковых новостях вместо того, чтобы бороться с ними. Я прочитал его речь (так быстрее, но можно и посмотреть), и должен сказать, что это действительно хороший текст. Не то чтобы он сказал что-то радикально новое — все критики интернет-гигантов повторяют более-менее те же тезисы. Но мнение Коэна интересно именно как мнение сатирика, провокатора, который сам регулярно ходит по краю и обижает многих своими некорректными шутками. Вспомните, сколько скандалов он спровоцировал в одном только образе Бората. И в то же время, сколько нездоровых стереотипов и предубеждений показал в своих фильмах — именно благодаря своим провокациям.
Коэн называет Facebook самой масштабной машиной пропаганды в истории, критикует оправдания Цукерберга ("Он говорит, что не знает, где провести черту между приемлемым и неприемлемым контентом? Да он просто имеет в виду, что это слишком дорого обходится его компании") и призывает регулировать интернет-компании так же, как и других вещателей. Власть миллиардеров из Долины, усиление голоса нездоровых идеологий, распространение теорий заговора — Коэн воспроизводит необходимый минимум из современной анти-"big tech" повестки, но также рассказывает и о собственных встречах с носителями опасных взглядов. Однажды он, представившись экспертом по борьбе с терроризмом из Израиля, нашёл американца, который поддерживал в соцсетях разные теории заговора. Это был обычный парень — образованный, с хорошей работой. И Коэн убедил его подложить взрывчатку на Марш женщин в Сан-Франциско — чтобы сорвать план антифа-террористов по обработке подгузников женскими гормонами, которые должны были превратить младенцев в трансгендеров. Парень был готов совершить массовое убийство, поверив в совершенно бредовый заговор.
После этого по-другому стал воспринимать провокации Коэна. Они действительно могут кого-то обидеть, но важнее — проблемы, которые при этом вскрываются. А ещё Коэн закончил Кэмбридж и писал диплом про американские правозащитные движения. Интересный парень, в общем.
Все мы знаем Сашу Барона Коэна как талантливого актёра и сатирика. На днях он раскрылся в новом амплуа: выступил на международном правозащитном саммите с критикой интернет-компаний, которые зарабатывают на хейтспиче и фейковых новостях вместо того, чтобы бороться с ними. Я прочитал его речь (так быстрее, но можно и посмотреть), и должен сказать, что это действительно хороший текст. Не то чтобы он сказал что-то радикально новое — все критики интернет-гигантов повторяют более-менее те же тезисы. Но мнение Коэна интересно именно как мнение сатирика, провокатора, который сам регулярно ходит по краю и обижает многих своими некорректными шутками. Вспомните, сколько скандалов он спровоцировал в одном только образе Бората. И в то же время, сколько нездоровых стереотипов и предубеждений показал в своих фильмах — именно благодаря своим провокациям.
Коэн называет Facebook самой масштабной машиной пропаганды в истории, критикует оправдания Цукерберга ("Он говорит, что не знает, где провести черту между приемлемым и неприемлемым контентом? Да он просто имеет в виду, что это слишком дорого обходится его компании") и призывает регулировать интернет-компании так же, как и других вещателей. Власть миллиардеров из Долины, усиление голоса нездоровых идеологий, распространение теорий заговора — Коэн воспроизводит необходимый минимум из современной анти-"big tech" повестки, но также рассказывает и о собственных встречах с носителями опасных взглядов. Однажды он, представившись экспертом по борьбе с терроризмом из Израиля, нашёл американца, который поддерживал в соцсетях разные теории заговора. Это был обычный парень — образованный, с хорошей работой. И Коэн убедил его подложить взрывчатку на Марш женщин в Сан-Франциско — чтобы сорвать план антифа-террористов по обработке подгузников женскими гормонами, которые должны были превратить младенцев в трансгендеров. Парень был готов совершить массовое убийство, поверив в совершенно бредовый заговор.
После этого по-другому стал воспринимать провокации Коэна. Они действительно могут кого-то обидеть, но важнее — проблемы, которые при этом вскрываются. А ещё Коэн закончил Кэмбридж и писал диплом про американские правозащитные движения. Интересный парень, в общем.
Кстати, о языках: в твиттере пишут, что Google Translate тестирует новый язык — инвесторский, вот пример перевода
Интересная идея — очки дополненной реальности для плавания, которые одновременно являются трекером. Прямо во время плавания вы видите свою скорость, время и дистанцию — эта информация выводится на небольшой OLED-экран на очках. Количество гребков, развороты и другие движения очки анализируют с помощью встроенного акселерометра и гироскопа. У вас может возникнуть вопрос — как очки могут трекать движения? Ответ прост — пловцов в очках снимали на видео, затем точные метрики взяли за основу для обучения и таким образом настроили сенсоры очков достаточно точно распознавать движения пловцов. Выглядит гаджет стильно и, если верить обзорам, действительно помогает пловцу рассчитать скорость на отдельных отрезках дистанции. Стоит недёшево — $200, эта игрушка явно не для любителей, но разработка интересная. Как и другие узкопрофильные применения AR — ведь универсальные AR-очки за такую цену пока, кажется, не нужны рынку.
FORM
FORM Smart Swim Goggles and Swim App
Swimmers at any skill level can be guided and motivated through an immersive swimming experience with the FORM Smart Swim Goggles and our Swim App.
Машинное обучение и Шекспировский вопрос
Есть много теорий насчёт авторства произведений Шекспира — вплоть до того, что на самом деле и не было вовсе никакого Шекспира. Менее радикальные гипотезы ставят под сомнение авторство отдельных пьес: к примеру, литературные критики ещё в 1850 году выдвинули теорию, что пьесу "Генрих VIII" Шекспир написал в соавторстве с Джоном Флетчером.
Чешский исследователь решил проверить эту теорию с помощью вычислений: он прогнал текст пьесы через нейросеть, обученную на текстах Шекспира и Флетчера (и ещё одного драматурга тех времён, для чистоты эксперимента). Программа сравнивала фрагменты текста по ритмике (последовательность ударных и безударных слогов) а также по часто употребляемым словам, и таким образом находила фрагменты, написанные в стиле Шекспира и, соответственно, Флетчера.
Результат — на графике. Несколько действий пьесы действительно написаны в характерном для Флетчера стиле — он часто писал ye вместо you, ’em вместо them, и добавлял в конце строки sir, still или next, выходя за рамки стандартного пятистопного ямба, которым часто писал Шекспир. Это исследование не отвечает однозначно на вопрос об авторстве пьесы. Но тепер у сторонников теории Флетчера есть аргументы, и даже указания на точные фрагменты текста, которые тот, возможно, написал.
https://arxiv.org/pdf/1911.05652.pdf
Есть много теорий насчёт авторства произведений Шекспира — вплоть до того, что на самом деле и не было вовсе никакого Шекспира. Менее радикальные гипотезы ставят под сомнение авторство отдельных пьес: к примеру, литературные критики ещё в 1850 году выдвинули теорию, что пьесу "Генрих VIII" Шекспир написал в соавторстве с Джоном Флетчером.
Чешский исследователь решил проверить эту теорию с помощью вычислений: он прогнал текст пьесы через нейросеть, обученную на текстах Шекспира и Флетчера (и ещё одного драматурга тех времён, для чистоты эксперимента). Программа сравнивала фрагменты текста по ритмике (последовательность ударных и безударных слогов) а также по часто употребляемым словам, и таким образом находила фрагменты, написанные в стиле Шекспира и, соответственно, Флетчера.
Результат — на графике. Несколько действий пьесы действительно написаны в характерном для Флетчера стиле — он часто писал ye вместо you, ’em вместо them, и добавлял в конце строки sir, still или next, выходя за рамки стандартного пятистопного ямба, которым часто писал Шекспир. Это исследование не отвечает однозначно на вопрос об авторстве пьесы. Но тепер у сторонников теории Флетчера есть аргументы, и даже указания на точные фрагменты текста, которые тот, возможно, написал.
https://arxiv.org/pdf/1911.05652.pdf
{kind=link}
Brodetskyi. Tech, VC, startups
Выступая в июне на конференции Recode, Билл Гейтс назвал две книги, которые следует прочитать, чтобы лучше понять проблематику искусственного интеллекта. Это "Суперинтеллект" Ника Бострома и "Верховный алгоритм" Педро Домингоса. Вторая книга недавно вышла…
Полезный лонгрид: саммари книги "Верховный алгоритм". Это научно-популярный бестселлер о машинном обучении, в котором автор рассматривает возможность создания самообучающегося супералгоритма, способного решать любые задачи. Книга не для программистов, там нет формул и кода — она для обычных людей, которые хотят понять, что такое машинное обучение. Эту книгу советует Билл Гейтс. Несколько глав из неё можно прочитать в свободном доступе — о цифровых двойниках и генетических алгоритмах. Но для начала лучше прочитать саммари — там все ключевые идеи.
Book Reviews
The Master Algorithm : Book Summary
This book gives a a macro picture of machine learning. In this post, I will briefly summarize the main points of the book. One can think of this post as a meta summary as the book itself is a…
Forwarded from Denis Sexy IT 🤖
Вы наверное помните, у Китая довольно большие проблему с Уйгурами — Китай всячески их притесняет, не так давно стало известно, что существуют «лагеря задержания», а регион где все это происходит оснащен максимальным количеством всевозможных устройств сбора данных.
На той неделе по цепи уйгуров в сеть утекла информация (CNN, BBC) для внутреннего пользования полиции Синьцзяна от 2017 года. В том числе секретные брифинги, которые показывают, как эта полиция получает приказы от огромного «кибернетического мозга», известного как IJOP, который помечает целые категории людей для расследования и задержания.
Утечка документов включает в себя:
• Руководство по эксплуатации для администрации лагерей задержания.
• Четыре коротких брифинга на китайском языке, известные как «бюллетени», в которых даются рекомендации по ежедневному использованию «Интегрированной платформы совместных операций» (IJOP), инструменты массового наблюдения и прогностической полицейской деятельности, которая анализирует данные из Синьцзяна.
В документах буквально идет речь о том, что некий алгоритм внутри IJOP, обученный на огромном количестве данных (от группы крови до показателей счетчиков электричества, IJOP приложения для полиции, в документе перечислены очень много параметров), способен решать, как задерживать и реагировать на потенциальных преступников, до факта преступления — это принято называть «предиктивная полицейская деятельность».
Например, в «Бюллетене № 14» содержится инструкция о том, как проводить массовые расследования и задержания после того, как IJOP сформировал длинный список подозреваемых. В документе сказано, что за 7 дней в июне 2017 года полицейские задержали 15 683 жителей Синьцзяна, помеченных IJOP, и поместили их в лагеря для интернированных
Это все выглядит как какой-то фильм или книга, где алгоритм решает как жить людям, но я склонен верить, что скорее всего так и есть, утечка подверждена множеством экспертов, включая лингвистический анализ. Страшно подумать, как за 3 года IJOP поумнел.
Правительство Китая утверждает, что все эти документы — фейк.
Весь лонгрид на тему слитых документов можно почитать тут.
На той неделе по цепи уйгуров в сеть утекла информация (CNN, BBC) для внутреннего пользования полиции Синьцзяна от 2017 года. В том числе секретные брифинги, которые показывают, как эта полиция получает приказы от огромного «кибернетического мозга», известного как IJOP, который помечает целые категории людей для расследования и задержания.
Утечка документов включает в себя:
• Руководство по эксплуатации для администрации лагерей задержания.
• Четыре коротких брифинга на китайском языке, известные как «бюллетени», в которых даются рекомендации по ежедневному использованию «Интегрированной платформы совместных операций» (IJOP), инструменты массового наблюдения и прогностической полицейской деятельности, которая анализирует данные из Синьцзяна.
В документах буквально идет речь о том, что некий алгоритм внутри IJOP, обученный на огромном количестве данных (от группы крови до показателей счетчиков электричества, IJOP приложения для полиции, в документе перечислены очень много параметров), способен решать, как задерживать и реагировать на потенциальных преступников, до факта преступления — это принято называть «предиктивная полицейская деятельность».
Например, в «Бюллетене № 14» содержится инструкция о том, как проводить массовые расследования и задержания после того, как IJOP сформировал длинный список подозреваемых. В документе сказано, что за 7 дней в июне 2017 года полицейские задержали 15 683 жителей Синьцзяна, помеченных IJOP, и поместили их в лагеря для интернированных
Это все выглядит как какой-то фильм или книга, где алгоритм решает как жить людям, но я склонен верить, что скорее всего так и есть, утечка подверждена множеством экспертов, включая лингвистический анализ. Страшно подумать, как за 3 года IJOP поумнел.
Правительство Китая утверждает, что все эти документы — фейк.
Весь лонгрид на тему слитых документов можно почитать тут.
Forwarded from wintermute
портал Gizmodo тут ругает кровососами компанию, которая обеспечивают интернет-услугами заключенных, и трудно не согласиться: с пораженных в правах капиталисты дерут буквально за все, в том числе за то, что мы бы с вами не догадались
например, компания GTL заключила контракт с департаментом исправительных учреждений штата Западная Виргиния, по которому взялась обеспечить каждого заключенного бесплатным планшетом. чтобы он мог ходить в интернет, читать книги, смотреть видео, отправлять письма и звонить родным и так далее
https://gizmodo.com/bloodsucking-prison-telecom-is-scamming-inmates-with-fr-1840056757
подвох в том, что доступ к разрешенному контенту стоит для зэков 5 центов в минуту, просмотр видео - 25 центов в минуту, отправка электронного письма - 25 центов за штуку, вложенное в письмо фото - 50 центов, видео - доллар. 15-минутный телефонный звонок обойдется примерно в 18 долларов. заключенные при этом зарабатывают от 4 до 25 центов в час, по утвержденным расценкам, то есть 15-минутный звонок это 12,5 часов работы
в принципе, никого не заставляют платить или даже брать халявные планшеты, но других провайдеров интернет-услуг в тюрьмах нет, плюс далеко не у всех бывают личные встречи с родными. давно обсуждающее предложение обеспечить зэков доступом к бесплатному Скайпу продолжает обсуждаться. оно и понятно - департаменту исправительных учреждений штата Колорадо та же GTL платит $800 тыс в год за право предоставлять зэкам услуги по таким вот адовым расценкам
в России зэков планшетами не обеспечивают, хотя с такими контрактами оно может и к лучшему. возьмем расценки сервиса ФСИН-ПИСЬМО, у нас письма будут даже дороже https://fsin-pismo.ru/client/app/letter/create
1 страница размером до 2500 знаков - 55 рублей (86 центов), плюс оплаченная стоимость ответа на одной странице - еще 55 рублей. фотография - 30 рублей (47 центов). максимальный размер письма составляет 8 страниц или 20000 знаков. количество писем и ответов в месяц не ограничено
легального доступа к интернету российские зэки не имеют - все отправленные им письма и фото просматриваются (впрочем, уверен, что в США тоже), распечатываются и на бумаге передаются заключенным, те пишут ответ, который потом переводится сотрудниками ФСИН в электронный вид и отправляется обратно. доступа к Скайпу или Ютубу тоже нет. нелегально, конечно, можно договориться, поэтому недавно тут ФСИН выступал с идеей ставить в колониях и тюрьмах глушилки сотовой связи (отчаявшись побороть коррупцию на местах). но вряд ли это сильно поможет #law #won
например, компания GTL заключила контракт с департаментом исправительных учреждений штата Западная Виргиния, по которому взялась обеспечить каждого заключенного бесплатным планшетом. чтобы он мог ходить в интернет, читать книги, смотреть видео, отправлять письма и звонить родным и так далее
https://gizmodo.com/bloodsucking-prison-telecom-is-scamming-inmates-with-fr-1840056757
подвох в том, что доступ к разрешенному контенту стоит для зэков 5 центов в минуту, просмотр видео - 25 центов в минуту, отправка электронного письма - 25 центов за штуку, вложенное в письмо фото - 50 центов, видео - доллар. 15-минутный телефонный звонок обойдется примерно в 18 долларов. заключенные при этом зарабатывают от 4 до 25 центов в час, по утвержденным расценкам, то есть 15-минутный звонок это 12,5 часов работы
в принципе, никого не заставляют платить или даже брать халявные планшеты, но других провайдеров интернет-услуг в тюрьмах нет, плюс далеко не у всех бывают личные встречи с родными. давно обсуждающее предложение обеспечить зэков доступом к бесплатному Скайпу продолжает обсуждаться. оно и понятно - департаменту исправительных учреждений штата Колорадо та же GTL платит $800 тыс в год за право предоставлять зэкам услуги по таким вот адовым расценкам
в России зэков планшетами не обеспечивают, хотя с такими контрактами оно может и к лучшему. возьмем расценки сервиса ФСИН-ПИСЬМО, у нас письма будут даже дороже https://fsin-pismo.ru/client/app/letter/create
1 страница размером до 2500 знаков - 55 рублей (86 центов), плюс оплаченная стоимость ответа на одной странице - еще 55 рублей. фотография - 30 рублей (47 центов). максимальный размер письма составляет 8 страниц или 20000 знаков. количество писем и ответов в месяц не ограничено
легального доступа к интернету российские зэки не имеют - все отправленные им письма и фото просматриваются (впрочем, уверен, что в США тоже), распечатываются и на бумаге передаются заключенным, те пишут ответ, который потом переводится сотрудниками ФСИН в электронный вид и отправляется обратно. доступа к Скайпу или Ютубу тоже нет. нелегально, конечно, можно договориться, поэтому недавно тут ФСИН выступал с идеей ставить в колониях и тюрьмах глушилки сотовой связи (отчаявшись побороть коррупцию на местах). но вряд ли это сильно поможет #law #won
Gizmodo
Bloodsucking Prison Telecom Is Scamming Inmates With 'Free' Tablets
When you get free technology, you can reasonably assume that you’re getting screwed. That’s infinitely truer if you’re in prison.
Forwarded from Let It Be Square
нейросеть научилась превращать всех в Джо Роганов – не только голос, но и образ: https://youtu.be/i7QNUZWS6VE
YouTube
RealTalk Returns: We Just Created The Deepest Deepfake Yet. Here's Why.
The world's first combination of realistic AI voice and video. Our intention behind this work is to demonstrate the power and danger of deepfakes for the general public. Read more here: https://tinyurl.com/dessa-deepfake
In this next phase of RealTalk, we’re…
In this next phase of RealTalk, we’re…
Forwarded from Малоизвестное интересное
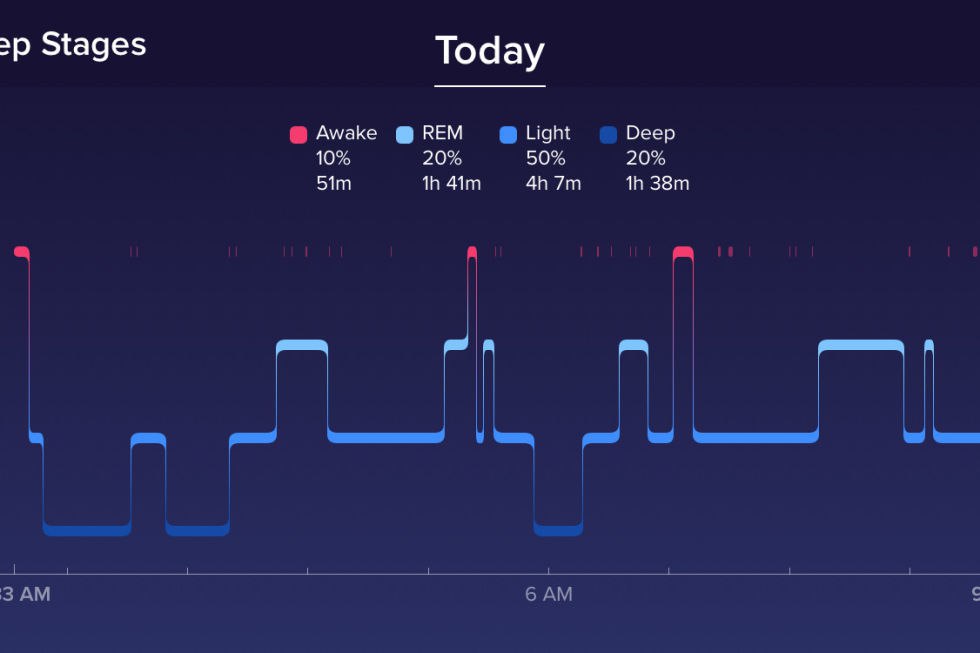
Преждевременное старение – от недосыпа.
Сон важнее спортзала и диеты против старения.
Лауреат Нобелевской премии, биолог, Элизабет Блэкберн вместе с психологом Элиссой Ипел написали книгу о том, как продлить свою жизнь, удлинив теломеры (структуры на концах хромосом, которые играют ключевую роль в клеточном старении и потому используются в качестве маркера биологического старения). Основная мысль книги «The Telomere Effect: A Revolutionary Approach to Living Younger, Healthier, Longer» (Теломерный эффект: революционный подход к более молодой, здоровой и долгой жизни) в том, что мы можем взять старение под контроль и тем самым замедлить его.
В книге рассказывается, что в нашем арсенале уже есть средства, которые помогают теломерам восстановиться. Ничего нового: 1. умеренные физические нагрузки 2. биодобавки и правильное питание 3. все, что снижает уровень стресса — главным образом, медитативные техники (коротко можно прочесть здесь https://theageofhappiness.com/posts/untitled/6eci52c5108).
И вот новый прорыв. Тщательно проведенное и хорошо документированное исследование на 482 сингапурских добровольцах показало существенную зависимость длины теломер от недосыпа и, в целом, от качества сна. Длина теломер у тех, кто спал менее пяти часов в сутки оказалась в среднем на 356 пар оснований меньше, чем у тех, кто спал в течение семи часов (с учетом возраста, пола, этнической принадлежности и прочих демографических, социально-экономических факторов и факторов образа жизни).
В основе этого прорывного исследования использование фитнес-трекера Fitbit Charge HR с функцией мониторинга сна. И получается, что именно контроль сна становится самой важной функцией этих гаджетов. Контроль физической нагрузки, конечно, тоже полезен. Но полноценный сон, как оказалось, еще важнее.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6778117/
#Сон #Старение
Сон важнее спортзала и диеты против старения.
Лауреат Нобелевской премии, биолог, Элизабет Блэкберн вместе с психологом Элиссой Ипел написали книгу о том, как продлить свою жизнь, удлинив теломеры (структуры на концах хромосом, которые играют ключевую роль в клеточном старении и потому используются в качестве маркера биологического старения). Основная мысль книги «The Telomere Effect: A Revolutionary Approach to Living Younger, Healthier, Longer» (Теломерный эффект: революционный подход к более молодой, здоровой и долгой жизни) в том, что мы можем взять старение под контроль и тем самым замедлить его.
В книге рассказывается, что в нашем арсенале уже есть средства, которые помогают теломерам восстановиться. Ничего нового: 1. умеренные физические нагрузки 2. биодобавки и правильное питание 3. все, что снижает уровень стресса — главным образом, медитативные техники (коротко можно прочесть здесь https://theageofhappiness.com/posts/untitled/6eci52c5108).
И вот новый прорыв. Тщательно проведенное и хорошо документированное исследование на 482 сингапурских добровольцах показало существенную зависимость длины теломер от недосыпа и, в целом, от качества сна. Длина теломер у тех, кто спал менее пяти часов в сутки оказалась в среднем на 356 пар оснований меньше, чем у тех, кто спал в течение семи часов (с учетом возраста, пола, этнической принадлежности и прочих демографических, социально-экономических факторов и факторов образа жизни).
В основе этого прорывного исследования использование фитнес-трекера Fitbit Charge HR с функцией мониторинга сна. И получается, что именно контроль сна становится самой важной функцией этих гаджетов. Контроль физической нагрузки, конечно, тоже полезен. Но полноценный сон, как оказалось, еще важнее.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6778117/
#Сон #Старение
{kind=link}
Forwarded from Гоша на дискотеке
О том, как Spotify следит за психологическим состоянием пользователей и продаёт собранную информацию рекламодателям:
Музыка, которую мы слушаем, замечательно отражает наши переживания. И сегодня стриминговые сервисы получили уникальную возможность собирать данные о настроениях своих пользователей. Отбросьте все иллюзии о приватности (если они еще остались) – любая онлайн-платформа записывает наши действия. Сервисы потокового воспроизведения музыки не стали исключением.
Даже зайдя в «приватный режим» Spotify (прим. – делает всю активность невидимой для друзей), пользователь все равно передает сервису данные о прослушиваниях. И благодаря повсеместному мониторингу Spotify превращается в одного из крупнейших мировых интернет-рекламодателей. Шведский стриминг генерирует сотни плейлистов, каждому из которых присваивает своё настроение: Mood Booster, Rage Beats, Life Sucks и так далее. Нужна энергичная утренняя музыка? Без проблем! Пытаетесь справиться с утратой? Найдется что-нибудь и для вас. Собрались всю ночь учиться? К вашим услугам Study Beats и тому подобные плейлисты.
Уже четыре года Spotify с помощью агрессивного маркетинга вещает о том, что их умные плейлисты это лучший способ навигации в океане из артистов и песен. Рекламные компании Spotify давно проходят под слоганом «Музыка для любого настроения». Но при ближайшем рассмотрении решение сервиса разделить подписчиков по настроенческим группам – это часть рекламной стратегии, которая помогла ему выйти на IPO. Данные об эмоциях стали главным магнитом для крупных компаний и маркетологов всех сортов и расцветок.
Впервые Spotify объявил о возможности мониторить психодемографиечские показатели еще в 2015 г, выкупив технологию «Music Intelligence» у компании Echo Nest. По мнению сервиса классифицировать миллениалов по жанрам музыки было уже глупо – они слушали почти все. Куда эффективней оказалось следить за их настроением. В том же году все бесплатные подписчики Spotify (прим. – около 60% от 180 млн. пользователей) начали получать рекламу, таргетированную по новой технологии.
Со временем сервис стал дополнять свои данные информацией о потребительских привычках, купленной у сторонних источников, и получать на выходе отличный рекламный инструмент, которым пользуются Dunkin’ Donuts, Snickers, Gatorade, BMW и маркетинговые гиганты типа WWP creative. Более того, Spotify научился предсказывать эмоции своих пользователей, составляя так называемые «emotional journey». То есть сейчас сервис знает какое количество пользователей будет находиться в той или иной настроенческой категории в будущем.
Что в итоге? В итоге Spotify научился собирать о пользователях уникальные сведения, которые не может предоставить ни одна другая IT-компания. Из положительных сторон такого мониторинга можно выделить тенденцию сервиса «выталкивать» людей на более позитивный эмоциональный уровень. Умные алгоритмы постепенно предлагают подписчикам в плохом настроении более положительные песни и, как показывает практика, те начинают с удовольствием их слушать. А логика такого решения Spotify диктуется хотя бы тем, что в хорошем настроении у людей повышается потребительская активность. Такой вот Mood-Boosting, способный в будущем сказаться на всей музыке, культуре и политике. Но надо отдать Spotify должное - в отличие от всех социальных сетей, только угнетающих психологию человека, стриминг занят ровно обратным.
Текст издания The Baffler:
http://bit.ly/2Zsj3Gb
Музыка, которую мы слушаем, замечательно отражает наши переживания. И сегодня стриминговые сервисы получили уникальную возможность собирать данные о настроениях своих пользователей. Отбросьте все иллюзии о приватности (если они еще остались) – любая онлайн-платформа записывает наши действия. Сервисы потокового воспроизведения музыки не стали исключением.
Даже зайдя в «приватный режим» Spotify (прим. – делает всю активность невидимой для друзей), пользователь все равно передает сервису данные о прослушиваниях. И благодаря повсеместному мониторингу Spotify превращается в одного из крупнейших мировых интернет-рекламодателей. Шведский стриминг генерирует сотни плейлистов, каждому из которых присваивает своё настроение: Mood Booster, Rage Beats, Life Sucks и так далее. Нужна энергичная утренняя музыка? Без проблем! Пытаетесь справиться с утратой? Найдется что-нибудь и для вас. Собрались всю ночь учиться? К вашим услугам Study Beats и тому подобные плейлисты.
Уже четыре года Spotify с помощью агрессивного маркетинга вещает о том, что их умные плейлисты это лучший способ навигации в океане из артистов и песен. Рекламные компании Spotify давно проходят под слоганом «Музыка для любого настроения». Но при ближайшем рассмотрении решение сервиса разделить подписчиков по настроенческим группам – это часть рекламной стратегии, которая помогла ему выйти на IPO. Данные об эмоциях стали главным магнитом для крупных компаний и маркетологов всех сортов и расцветок.
Впервые Spotify объявил о возможности мониторить психодемографиечские показатели еще в 2015 г, выкупив технологию «Music Intelligence» у компании Echo Nest. По мнению сервиса классифицировать миллениалов по жанрам музыки было уже глупо – они слушали почти все. Куда эффективней оказалось следить за их настроением. В том же году все бесплатные подписчики Spotify (прим. – около 60% от 180 млн. пользователей) начали получать рекламу, таргетированную по новой технологии.
Со временем сервис стал дополнять свои данные информацией о потребительских привычках, купленной у сторонних источников, и получать на выходе отличный рекламный инструмент, которым пользуются Dunkin’ Donuts, Snickers, Gatorade, BMW и маркетинговые гиганты типа WWP creative. Более того, Spotify научился предсказывать эмоции своих пользователей, составляя так называемые «emotional journey». То есть сейчас сервис знает какое количество пользователей будет находиться в той или иной настроенческой категории в будущем.
Что в итоге? В итоге Spotify научился собирать о пользователях уникальные сведения, которые не может предоставить ни одна другая IT-компания. Из положительных сторон такого мониторинга можно выделить тенденцию сервиса «выталкивать» людей на более позитивный эмоциональный уровень. Умные алгоритмы постепенно предлагают подписчикам в плохом настроении более положительные песни и, как показывает практика, те начинают с удовольствием их слушать. А логика такого решения Spotify диктуется хотя бы тем, что в хорошем настроении у людей повышается потребительская активность. Такой вот Mood-Boosting, способный в будущем сказаться на всей музыке, культуре и политике. Но надо отдать Spotify должное - в отличие от всех социальных сетей, только угнетающих психологию человека, стриминг занят ровно обратным.
Текст издания The Baffler:
http://bit.ly/2Zsj3Gb
The Baffler
Big Mood Machine
Inside Spotify’s emotional surveillance-driven quest for total ad domination.
Очень странная новость, просто оставлю здесь без комментариев: видео, заметка
“Это портрет Бориса Евгеньевича Патона, которому завтра исполняется 101 год. И это первый портрет конкретного человека, сделанный искусственным интеллектом. Он считается эталоном фотоискусства ХХI века. То есть это уже шедевр”, - подчеркнул Мельникофф.
Он рассказал, что оригинальный файл портрета - 4 х 4 метра - это финальная стадия реализации культурного проекта стоимостью в полмиллиона долларов и года упорного труда, что для создания портрета высококлассными программистами был написан специальный алгоритм.
“Мы загрузили в суперкомпьютер больше 2 тысяч фотографий, обработанных в высоком полиграфическом качестве. Это фотографии Бориса Патона, начиная с 1920-ых годов. Он предоставил семейные альбомы, мы попросили НАН Украины и забрали все, что у них есть. Мы отобрали 2 тысячи для работы компьютера”, - поведал основатель Фонда. Он уточнил, что весь массив занимал сотни гигабайт, для чего понадобился суперкомпьютер.
Другими словами, руководитель некого странного фонда загрузил в нейросеть 2000 фотографий академика Патона, чтобы получить его усредненный портрет, и потратил на это полмиллиона долларов.
🤯
UPD Читатели прислали биографию этого деятеля, она многое объясняет:
https://meduza.io/feature/2015/10/13/razgrom-rizhskoy-vystavki-lyudi-maydana-korotko-i-bezumno. Я бы и не постил такой явный буллшит, но новость об этом "достижении" сильно задела украинское ИИ-комьюнити.
“Это портрет Бориса Евгеньевича Патона, которому завтра исполняется 101 год. И это первый портрет конкретного человека, сделанный искусственным интеллектом. Он считается эталоном фотоискусства ХХI века. То есть это уже шедевр”, - подчеркнул Мельникофф.
Он рассказал, что оригинальный файл портрета - 4 х 4 метра - это финальная стадия реализации культурного проекта стоимостью в полмиллиона долларов и года упорного труда, что для создания портрета высококлассными программистами был написан специальный алгоритм.
“Мы загрузили в суперкомпьютер больше 2 тысяч фотографий, обработанных в высоком полиграфическом качестве. Это фотографии Бориса Патона, начиная с 1920-ых годов. Он предоставил семейные альбомы, мы попросили НАН Украины и забрали все, что у них есть. Мы отобрали 2 тысячи для работы компьютера”, - поведал основатель Фонда. Он уточнил, что весь массив занимал сотни гигабайт, для чего понадобился суперкомпьютер.
Другими словами, руководитель некого странного фонда загрузил в нейросеть 2000 фотографий академика Патона, чтобы получить его усредненный портрет, и потратил на это полмиллиона долларов.
🤯
UPD Читатели прислали биографию этого деятеля, она многое объясняет:
https://meduza.io/feature/2015/10/13/razgrom-rizhskoy-vystavki-lyudi-maydana-korotko-i-bezumno. Я бы и не постил такой явный буллшит, но новость об этом "достижении" сильно задела украинское ИИ-комьюнити.
Forwarded from Цифровой этикет
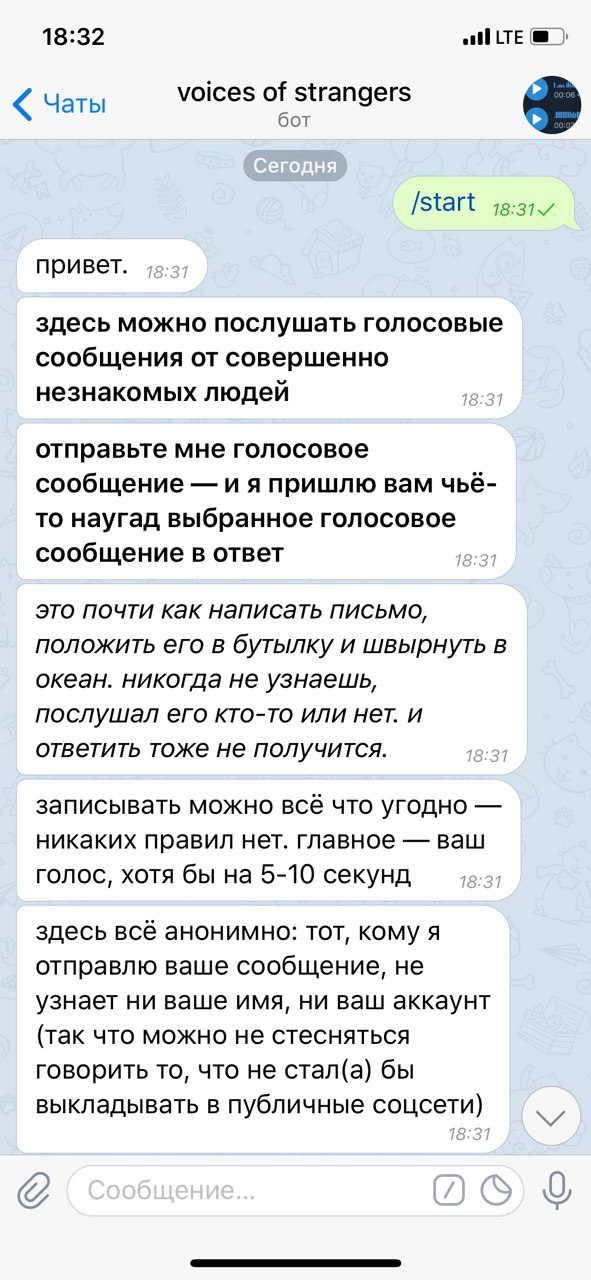
В телеграме появился бот Voices of Strangers. Вы отправляете боту любое голосовое сообщение. В ответ он присылает вам чужое голосовое сообщение от неизвестного человека. Ваше голосовое сообщение также позже может услышать другой человек, который воспользуется ботом.
«Афиша» опубликовала интервью с создателем этого бота Евгением Кудашевым. Он считает, что бот стал завоевывать популярность (за первые 10 часов набралось 10 тыс. сообщений), потому что людям или скучно или одиноко, или и то и другое.
Я прослушала 3 сообщения. В одном кто-то делал 8 секунд «фырфырфыр», в другом девушка предложила делиться постыдными секретами, а в третьем меня послали матом.
«К сожалению, наряду с людьми, которые пользуются этим проектом так, как задумывалось, — рассказывают искренние личные истории и всячески вовлекаются в общение с незнакомцами — другие люди засоряют это пространство тишиной, бессмысленными глупостями, оскорблениями, и так далее. Это репрезентация того, как себя ведет общество». Похоже, это отлично демонстрирует то, как одурманивающе действует на нас анонимность и безнаказанность.
«Афиша» опубликовала интервью с создателем этого бота Евгением Кудашевым. Он считает, что бот стал завоевывать популярность (за первые 10 часов набралось 10 тыс. сообщений), потому что людям или скучно или одиноко, или и то и другое.
Я прослушала 3 сообщения. В одном кто-то делал 8 секунд «фырфырфыр», в другом девушка предложила делиться постыдными секретами, а в третьем меня послали матом.
«К сожалению, наряду с людьми, которые пользуются этим проектом так, как задумывалось, — рассказывают искренние личные истории и всячески вовлекаются в общение с незнакомцами — другие люди засоряют это пространство тишиной, бессмысленными глупостями, оскорблениями, и так далее. Это репрезентация того, как себя ведет общество». Похоже, это отлично демонстрирует то, как одурманивающе действует на нас анонимность и безнаказанность.
{kind=link}
Forwarded from Малоизвестное интересное
Король ИИ голый, и ему нужно либо трусы надеть, либо крестик снять.
Франсуа Шолле из Google написал правду, которую его компания не может пока открыто признать.
Принципиальная ошибка современной науки и технологий ИИ в том, что они развиваются в условиях, когда:
- мы так и не договорились, что понимаем под ИИ;
- у нас нет способа сравнить ИИ между собой и с интеллектом человека.
В результате
(1) мы разрабатываем нечто, что помогает нам решать конкретные задачи, но, возможно, не является при этом интеллектом: ни подобием человеческого (об определении которого мы не договорились), ни искусственным (поскольку невозможно сделать искусственную сепульку, не договорившись, что такое натуральная сепулька);
(2) мы не в состоянии реально оценивать прогресс в создании ИИ, поскольку:
- не определились с направлением «куда плывем»;
- не договорились, как оценивать достигнутое (сравнивать разные интеллекты по «интеллектуальности»).
В итоге мы подобны морякам, отправившимся в далекое плавание, не договорившись, куда плывут, и не имея средств определения текущего местоположения.
В общем, ситуация тупиковая, не смотря на явный прогресс в прикладном использовании машинного обучения.
Ибо:
- с машинным обучением все ОК;
- а с созданием ИИ полная Ж.
И поэтому существующую парадигму ИИ необходимо кардинально менять.
Все вышесказанное - не просто мой очередной призыв к читателям канала «Малоизвестное интересное». Это преамбула к 60ти страничному «манифесту» On the Measure of Intelligence, на днях опубликованном Франсуа Шнолле – известным исследователем ИИ в компании Google, создателем библиотеки глубокого обучения Keras и соразработчиком фреймворка машинного обучения TensorFlow.
Шнолле сделал то, что не может позволить себе Google: открыто заявить – король ИИ голый, и ему нужно либо трусы надеть, либо крестик снять.
Ну а теперь о главном.
Главная ценность «Манифеста Шолле» не в его смелости и точности формулировок. А в том, что предложена четкая альтернатива, детально сформулировавшая (1) куда плыть и (2) как измерять свое местоположение на пути к цели (как сравнивать создаваемые интеллекты между собой и человеком).
Дочитать, что конкретно предложил Франсуа Шолле - на 90 сек. чтения в моем посте
- на Medium http://bit.do/fji34
- на Яндекс Дзен https://clck.ru/KZuPs
#ИИ
Франсуа Шолле из Google написал правду, которую его компания не может пока открыто признать.
Принципиальная ошибка современной науки и технологий ИИ в том, что они развиваются в условиях, когда:
- мы так и не договорились, что понимаем под ИИ;
- у нас нет способа сравнить ИИ между собой и с интеллектом человека.
В результате
(1) мы разрабатываем нечто, что помогает нам решать конкретные задачи, но, возможно, не является при этом интеллектом: ни подобием человеческого (об определении которого мы не договорились), ни искусственным (поскольку невозможно сделать искусственную сепульку, не договорившись, что такое натуральная сепулька);
(2) мы не в состоянии реально оценивать прогресс в создании ИИ, поскольку:
- не определились с направлением «куда плывем»;
- не договорились, как оценивать достигнутое (сравнивать разные интеллекты по «интеллектуальности»).
В итоге мы подобны морякам, отправившимся в далекое плавание, не договорившись, куда плывут, и не имея средств определения текущего местоположения.
В общем, ситуация тупиковая, не смотря на явный прогресс в прикладном использовании машинного обучения.
Ибо:
- с машинным обучением все ОК;
- а с созданием ИИ полная Ж.
И поэтому существующую парадигму ИИ необходимо кардинально менять.
Все вышесказанное - не просто мой очередной призыв к читателям канала «Малоизвестное интересное». Это преамбула к 60ти страничному «манифесту» On the Measure of Intelligence, на днях опубликованном Франсуа Шнолле – известным исследователем ИИ в компании Google, создателем библиотеки глубокого обучения Keras и соразработчиком фреймворка машинного обучения TensorFlow.
Шнолле сделал то, что не может позволить себе Google: открыто заявить – король ИИ голый, и ему нужно либо трусы надеть, либо крестик снять.
Ну а теперь о главном.
Главная ценность «Манифеста Шолле» не в его смелости и точности формулировок. А в том, что предложена четкая альтернатива, детально сформулировавшая (1) куда плыть и (2) как измерять свое местоположение на пути к цели (как сравнивать создаваемые интеллекты между собой и человеком).
Дочитать, что конкретно предложил Франсуа Шолле - на 90 сек. чтения в моем посте
- на Medium http://bit.do/fji34
- на Яндекс Дзен https://clck.ru/KZuPs
#ИИ